背景介绍
优化章节已更新:https://yejiongkai.github.io/2025/05/15/track-rk3588-3-2/
研究现状
目前市面上已经有不少无人机跟踪器,一般都提供了目标检测和目标跟踪功能,这两个功能的作用我总结如下:
- 目标检测:基于图像,无需上下文信息。
- 优点:提供特定类别自主搜索能力,识别精度较高,泛化能力强,可以充分利用NPU多线程计算。
- 缺点:全局搜索耗时长,延迟较大,对于实时性较强的场景不太使用。
- 目标跟踪:基于视频,需要上下文信息(前一帧的目标坐标)。
- 优点:可以跟踪特定目标(如一个特定的人),局部搜索耗时短,延迟较小,实时性好。
- 缺点:需要先给定目标坐标才能跟踪,目标特征变化过大容易丢失,无法利用NPU多线程计算。
通过将目标检测和目标跟踪相结合,先用目标检测自主目标定位,然后通过目标跟踪进行持续跟踪。除此之外也有采用多目标跟踪算法(如ByteTrack和DeepSort),通过目标检测获取每一帧目标坐标,再通过目标关联算法将前后帧的目标进行匹配。但是这种方法需要持续的进行目标检测,实时性并没有单目标跟踪算法好。所以我采用的也是目标检测+目标跟踪的方法进行跟踪器设计。
研究意义
在确定了跟踪方案以后,作为一名研究牲,就要开始思考如何做出自己的特色了。目前市面上的产品,目标检测和目标跟踪算法的融合度并不高,大多是互补的方案,用目标检测去定位,用目标跟踪去跟踪,丢失后再用目标检测去找。那我要是把目标检测也用来跟踪,再与目标跟踪的结果进行融合,做到保证实时性的情况下进一步提高跟踪性能,哎,创新点不就来了嘛。
评价指标
确定了方案和优化目标,就需要评价指标来判断跟踪效果的好坏,这里我用跟踪延迟和跟踪帧率来评价跟踪器性能的好坏。
注意:暂时还未考虑跟踪精度的评价指标,这里只考虑云台控制效果
历史经验和难点分析
这里记录一下我之前做跟踪器的相关经历和遇到的难点,为下文的优化进行铺垫。
首先是我做过的一些实验:
- 单独使用目标检测进行单目标跟踪
- 人工提供坐标框使用单目标跟踪算法进行跟踪
- 使用目标检测获取坐标框,再用单目标跟踪算法进行跟踪,丢失再用目标检测重新搜索
然后列出上述方案各自存在的问题:
- 对目标检测结果依赖性过强,实时性差,难以针对指定目标进行跟踪(若目标类别重叠容易跟错)
- 需要人工干涉,目标特征变化过大或目标移动速度过快容易导致跟踪丢失,且无法找回
- 目标检测选择的目标特征可能较为稀疏不利于后续跟踪,丢失后再次用目标检测搜索容易跟错目标
结合上述问题,我对跟踪器的优化目标进行总结:
- 可以自主选择目标(对目标检测结果进行优化)
- 可以长时间针对特定目标进行跟踪(对单目标跟踪特征信息进行优化)
- 跟踪丢失时(遮掩或高速运动)可以再次找回上一次跟踪的目标(目标检测和目标跟踪融合)。
模块功能
基类介绍
既然是在RK3588平台上进行推理,就要用到RKNPU的API对NPU进行调度。调度NPU的主要步骤包括加载模型(初始化rknn_context),读取和设置模型参数(输入输出个数,尺寸和类型,量化类型,NPU调度策略),输入推理数据(rknn_input或零拷贝),推理计算(rknn_run)和获取推理结果(rknn_output)。该过程较为繁琐且重复,所以将其封装成一个基类提供简化的访问接口,这样用户只需关心输入输出数据的格式即可。由于RKNPU还支持零拷贝(提前分配一块物理内存,直接对该内存进行输入数据拷贝),所以提供了两套基类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
class BaseModel_ZC {
public:
BaseModel_ZC();
BaseModel_ZC(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int load_rknn_model(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int run();
int set_core_mask(int num);
virtual int preprocess(image_buffer_t *img);
virtual int preprocess(feature_buffer_t *img1, feature_buffer_t *img2);
virtual int postprocess();
virtual ~BaseModel_ZC();
protected:
rknn_context rknn_ctx;
rknn_input_output_num io_num;
rknn_tensor_attr* input_attrs;
rknn_tensor_attr* output_attrs;
rknn_output* outputs;
rknn_tensor_mem** input_mems;
rknn_tensor_mem** output_mems;
rknn_tensor_attr* input_native_attrs;
rknn_tensor_attr* output_native_attrs;
int model_channel;
int model_width;
int model_height;
bool is_quant;
};
class BaseModel {
public:
BaseModel();
BaseModel(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int load_rknn_model(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int run();
int set_core_mask(int num);
virtual int preprocess(image_buffer_t *img);
virtual int preprocess(feature_buffer_t *img1, feature_buffer_t *img2);
virtual int postprocess();
virtual ~BaseModel();
protected:
rknn_context rknn_ctx;
rknn_input_output_num io_num;
rknn_tensor_attr* input_attrs;
rknn_tensor_attr* output_attrs;
rknn_output* outputs;
rknn_input* inputs;
int model_channel;
int model_width;
int model_height;
bool is_quant;
};
|
用户可根据需求继承上述两个基类中的一个,然后覆写前处理函数preprocess和后处理函数postprocess即可。
YOLOV8目标检测
瑞芯微对YOLO系列的模型优化较好,所以我选择YOLOV8作为目标检测模型,YOLOV8的模型部署可以在rknn_model_zoo里面找到,我基于zoo结合我的项目设计YOLOV8类如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class YoloModel: public BaseModel_ZC {
public:
YoloModel(): BaseModel_ZC() {}
YoloModel(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type): BaseModel_ZC(path, input_type, output_type) {}
int preprocess(image_buffer_t *img) override;
int postprocess() override;
int search(image_rect_t* dst, int width, int height, int label, int flag);
int search(image_rect_t* dst, image_rect_t* target, int label, int flag);
int draw_result(image_buffer_t *img);
char** get_labels();
friend int init_post_process(YoloModel& model, const char* path);
friend int post_process(YoloModel& model, float conf_threshold, float nms_threshold);
~YoloModel();
protected:
const float nms_threshold = NMS_THRESH;
const float box_conf_threshold = BOX_THRESH;
char *labels[OBJ_CLASS_NUM];
letterbox_t letter_box;
object_detect_result_list od_results;
};
|
Nanotrack目标跟踪
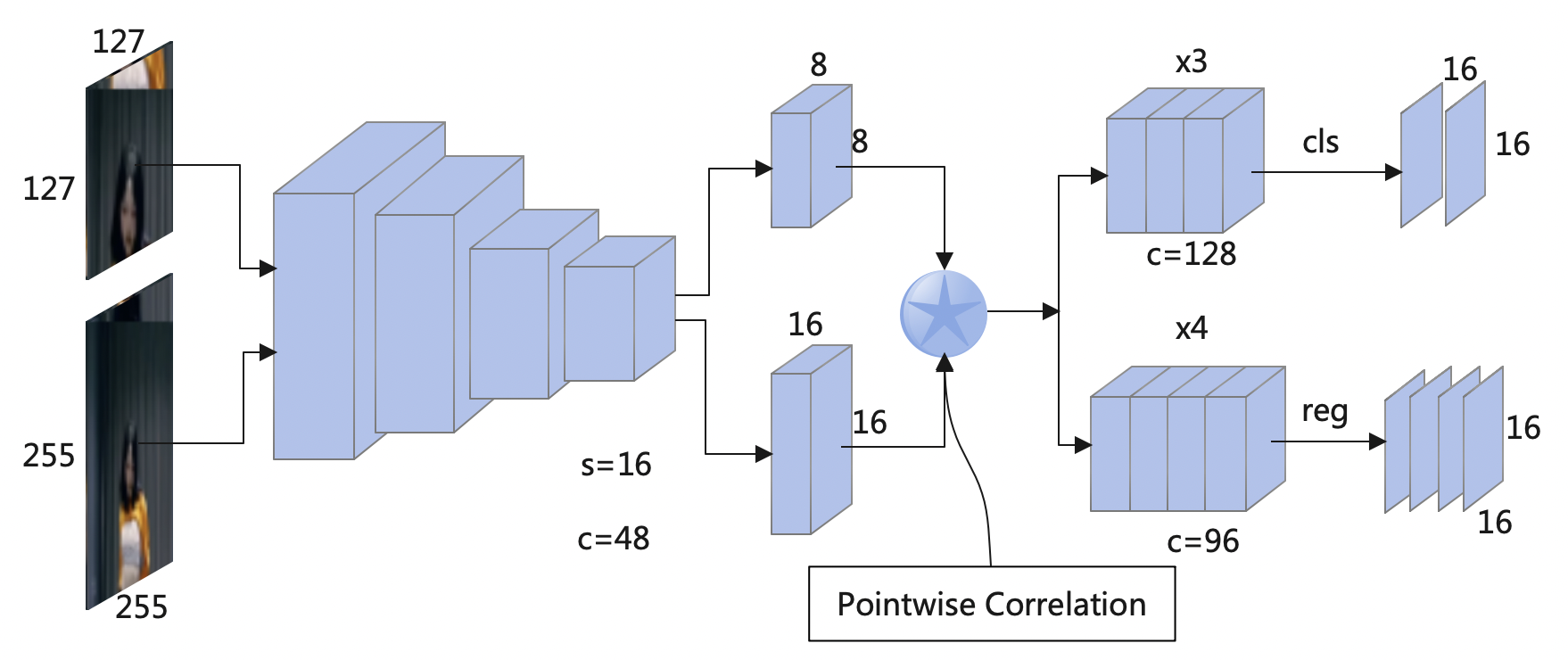
官方并没有提供Nanotrack的c++部署案例,所以需要我们自己对Nanotrack模型进行转换和部署。Nanotrack是专门针对嵌入式部署设计的目标跟踪模型,其模型参数量少,但又能提供较高跟踪性能。
| Trackers |
Backbone Size(*.onnx) |
Head Size (*.onnx) |
FLOPs |
Parameters |
| NanoTrackV1 |
752K |
384K |
75.6M |
287.9K |
| NanoTrackV2 |
1.0M |
712K |
84.6M |
334.1K |
| NanoTrackV3 |
1.4M |
1.1M |
115.6M |
541.4K |
1. 模型下载
首先获取模型源码,这里我使用的是HonglinChu 的项目,里面包含了2020-2022的Siamese系列的单目标跟踪算法。
1
| git clone https://github.com/HonglinChu/SiamTrackers.git
|
2. 模型拆分
由于Nanotrack由模板特征提取网络,搜索区域特征提取网络和特征匹配网络三部分组成,所以我们需要将这三部分拆开成单独的权重文件。这里提供一个python脚本进行拆解,通过torch.jit将动态计算图转换为静态计算图方便模型部署。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import argparse
import os
import torch
import sys
sys.path.append(os.getcwd())
from nanotrack.core.config import cfg
from nanotrack.utils.model_load import load_pretrain
from nanotrack.models.model_builder import ModelBuilder
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
parser = argparse.ArgumentParser(description='lighttrack')
parser.add_argument('--config', type=str, default='./models/config/configv2.yaml',help='config file')
parser.add_argument('--snapshot', default='models/pretrained/nanotrackv2.pth', type=str, help='snapshot models to eval')
args = parser.parse_args()
def main():
cfg.merge_from_file(args.config)
model = ModelBuilder()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = load_pretrain(model, args.snapshot)
model.eval().to(device)
backbone_net = model.backbone
head_net = model.ban_head
backbone_net_127 = torch.jit.trace(backbone_net, torch.Tensor(1, 3, 127, 127))
backbone_net_127.save('./models/pt/backbone_127.pt')
backbone_net_255 = torch.jit.trace(backbone_net, torch.Tensor(1, 3, 255, 255))
backbone_net_255.save('./models/pt/backbone_255.pt')
trace_model = torch.jit.trace(head_net, (torch.Tensor(1, 48, 8, 8), torch.Tensor(1, 48, 16, 16)))
trace_model.save('./models/pt/head.pt')
if __name__ == '__main__':
main()
|
3. 模型转换
有了backbone_127.pt,backbone_255.pt和head.pt文件后,就可以使用rknn-toolkit2进行模型转换,具体过程我就不详细介绍了。
4. 类实现
单目标跟踪相比目标检测,其流程会麻烦一些,需要先获取模板特征向量,然后获取搜索区域特征向量,最后将两个特征向量进行互相关获得目标所在位置。所以我构造了一个Backbone类负责特征提取,Banhead类负责特征匹配,最后构造Nanotrack类封装整个跟踪所需功能。定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| class Backbone: public BaseModel {
public:
Backbone(): BaseModel(), is_malloc(false) { src_img.virt_addr=nullptr; result.virt_addr=nullptr; }
Backbone(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type):
BaseModel(path, input_type, output_type), is_malloc(false) { src_img.virt_addr=nullptr; result.virt_addr=nullptr; }
int preprocess(image_buffer_t *img) override;
int postprocess() override;
feature_buffer_t* get_result();
~Backbone();
private:
image_buffer_t src_img;
feature_buffer_t result;
bool is_malloc;
};
class Banhead: public BaseModel {
public:
Banhead(): window(nullptr), grid_to_search_x(nullptr), grid_to_search_y(nullptr), cls_score(0.0) { this->create_window_grid(); }
Banhead(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type): BaseModel(path, input_type, output_type),
window(nullptr), grid_to_search_x(nullptr), grid_to_search_y(nullptr), cls_score(0.0) { this->create_window_grid(); }
int preprocess(feature_buffer_t *feature1, feature_buffer_t *feature2) override;
int postprocess() override;
void create_window_grid();
float* get_result_pos();
float get_cls_score();
~Banhead();
private:
float* grid_to_search_x;
float* grid_to_search_y;
float* window;
float cls_score;
float result_xywh[4];
};
class NanoTrack {
public:
NanoTrack(): backbone_T(nullptr), backbone_X(nullptr), ban_head(nullptr), result_T(nullptr), result_X(nullptr) {}
int load_backbone_T(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int load_backbone_X(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int load_ban_head(const std::string& path, rknn_tensor_type input_type, rknn_tensor_type output_type);
int init(image_buffer_t* img, image_rect_t* rect);
int track(image_buffer_t* img);
int get_result(image_rect_t* box, float* score);
int draw_result(image_buffer_t *img);
~NanoTrack();
private:
Backbone* backbone_X;
Backbone* backbone_T;
Banhead* ban_head;
Config cfg;
State state;
feature_buffer_t *result_T, *result_X;
};
|
检测跟踪一体化框架
在介绍了上述目标检测和单目标跟踪模块后,就可以将两者进行决策级融合构建检测跟踪一体化框架,实现上述提到的优化目标。由于这个模块还在持续不断改进,后续若效果还能进一步提升会再次更新章节内容。
框架介绍
这里介绍如何设计框架并进行决策级融合,其中会涉及到多种状态,采用状态机可以完美描述每个状态的工作内容,还能闭环整个工作的运行流程,避免BUG的产生。
状态类型
目前我将整个跟踪器的状态分成下面7种
1
2
3
4
5
6
7
8
9
10
| typedef enum _track_state {
TRACK_STATE_CLOSE,
TRACK_STATE_START,
TRACK_STATE_RESET,
TRACK_STATE_FIRST,
TRACK_STATE_LOCK,
TRACK_STATE_CORRECT,
TRACK_STATE_LOSS,
} track_state;
|
其定义如下:
- TRACK_STATE_CLOSE: 关闭检测跟踪功能,该状态下会直接退出状态机管理
- TRACK_STATE_START: 开启检测跟踪功能,该状态会负责进行一些初始化工作,并进入FIRST阶段
- TRACK_STATE_RESET: 重置检测跟踪功能,该状态用于复位舵机和重新开始检测目标
- TRACK_STATE_FIRST: 检测目标并进行选择需要跟踪的目标,再选择完目标后进入LOCK阶段
- TRACK_STATE_LOCK: 对目标进行锁定跟踪,若跟踪丢失会进入LOSS阶段,若长时间坐标未改变会进入CORRECT阶段
- TRACK_STATE_CORRECT: 对跟踪目标进行检测校验,用于判断跟踪模块是否进入伪跟踪情况。
- TRACK_STATE_LOSS: 目标跟踪丢失状态,使用检测模型对附件区域进行搜索找回。
这里提一下伪跟踪的意思是跟踪模型实际上已经跟丢目标,但是它依旧认为锁定的区域是跟丢的目标,引起误判,此时跟踪器会一直锁定在一个固定位置,这时就需要检测模型判断该区域是否包含目标来校准。
状态机
这些放出我实现的状态机代码,部分状态还没有补全,等我持续完善后再更新。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
| switch(track_state) {
case TRACK_STATE_CLOSE: {
#ifdef DEBUG
std::cout << "cur track state is close" << std::endl;
#endif
break;
}
case TRACK_STATE_START: {
#ifdef DEBUG
std::cout << "track is about to start" << std::endl;
#endif
track_state = TRACK_STATE_FIRST;
break;
}
case TRACK_STATE_RESET: {
servo_controler.set_angle(90, 90);
track_state = TRACK_STATE_START;
break;
}
case TRACK_STATE_FIRST: {
yolo_model.preprocess(&src_image);
yolo_model.run();
yolo_model.postprocess();
ret = yolo_model.search(&cur_rect, VIDEO_FRAME_WIDTH, VIDEO_FRAME_HEIGHT, label_cls, SEARCH_MAX_RECT);
if(ret < 0) {
#ifdef DEBUG
std::cout << "Not find " << labels[label_cls] << std::endl;
#endif
}
else {
last_rect.left = cur_rect.left;
last_rect.right = cur_rect.right;
last_rect.top = cur_rect.top;
last_rect.bottom = cur_rect.bottom;
ret = tracker.init(&src_image, &last_rect);
if(ret < 0) {
std::cout << "tracker init failed" << std::endl;
}
ret = tracker.track(&src_image);
tracker.get_result(&cur_rect, &track_score);
if(track_score < TRACK_SCORE_THRESH) {
std::cout << "Feature is unstable" << std::endl;
}
else track_state = TRACK_STATE_LOCK;
}
break;
}
case TRACK_STATE_LOCK: {
ret = tracker.track(&src_image);
tracker.get_result(&cur_rect, &track_score);
if(track_score < TRACK_SCORE_THRESH) {
ret = -1;
}
if(ret < 0) {
#ifdef DEBUG
std::cout << "LOCK: Not find " << labels[label_cls] << std::endl;
#endif
track_loss_num++;
track_state = TRACK_STATE_LOSS;
}
else {
last_rect.left = cur_rect.left;
last_rect.right = cur_rect.right;
last_rect.top = cur_rect.top;
last_rect.bottom = cur_rect.bottom;
draw_circle(&src_image, (cur_rect.left+cur_rect.right)/2, (cur_rect.top+cur_rect.bottom)/2, 3, 127, 3);
servo_controler.do_filter((double)(cur_rect.left+cur_rect.right)/2, (double)(cur_rect.top+cur_rect.bottom)/2);
if(track_gap > TRACK_GAP) {
int is_move = servo_controler.do_track();
if(is_move) {
track_static_count = 0;
}
else {
++track_static_count;
if(track_static_count > TRACK_STATIC_THRESH) {
track_state = TRACK_STATE_CORRECT;
track_static_count = 0;
}
}
track_gap = 0;
}
else ++track_gap;
draw_circle(&src_image, servo_controler.get_target().first, servo_controler.get_target().second, 3, 200, 3);
tracker.draw_result(&src_image);
}
break;
}
case TRACK_STATE_CORRECT: {
yolo_model.preprocess(&src_image);
yolo_model.run();
yolo_model.postprocess();
ret = yolo_model.search(&cur_rect, &last_rect, label_cls, SEARCH_NEAR);
if(ret < 0) {
#ifdef DEBUG
std::cout << "CORRECT: Not find" << labels[label_cls] << std::endl;
#endif
track_state = TRACK_STATE_LOSS;
}
else {
#ifdef DEBUG
std::cout << "CORRECT: correct successfully" << std::endl;
#endif
track_state = TRACK_STATE_LOCK;
}
break;
}
case TRACK_STATE_LOSS: {
yolo_model.preprocess(&src_image);
yolo_model.run();
yolo_model.postprocess();
ret = yolo_model.search(&cur_rect, &last_rect, label_cls, SEARCH_NEAR);
if(ret < 0) {
#ifdef DEBUG
std::cout << "LOSS: Not find " << labels[label_cls] << "track_loss_num: " << track_loss_num << std::endl;
#endif
track_loss_num++;
if(track_loss_num >= TRACK_LOSS_NUM) {
#ifdef DEBUG
std::cout << "LOSS: give up search again " << std::endl;
#endif
track_loss_num = 0;
track_state = TRACK_STATE_FIRST;
}
}
else {
#ifdef DEBUG
std::cout << "Success find track object again" << std::endl;
#endif
track_state = TRACK_STATE_LOCK;
last_rect.left = cur_rect.left;
last_rect.right = cur_rect.right;
last_rect.top = cur_rect.top;
last_rect.bottom = cur_rect.bottom;
track_loss_num = 0;
ret = tracker.init(&src_image, &last_rect);
}
break;
}
default: {
std::cout << "Unkown track state" << std::endl;
break;
}
}
|